










A CRUD(e) Approach - Part 1
- 1 avr. 2019
- 3 min de lecture
Sometimes, things just fit, in a right timing. I wanted to write about new concepts that I've been learning in my new job, and also wanted to follow up on my previous post with some better illustrations. And here I am, writing about both!
CRUD stands for Create/Read/Update/Delete. Rather simple actions, and I'm sure they can apply to some data/entity/object/thing in the last application you wrote. While the CRUD acronym usually applies to persistent storage, like a database, you don't necessarily want to have a MySQL running next to your application as it involves some heavy work to set up, maintain, back up... and you could just use some simple API to manage this data locally. That's what CRUD is for : abstracting how the data is being accessed (from memory or database) by having a single, simple interface to it. If you want to drift away, have a look a this pretty good article on the Repository Pattern.
Disclaimer: like any other pattern, this pattern must be used if you have a good reason to do so. If you need a customized, full-featured API instead of a simple generic set of methods that are primarily made to mirror a database, then go for it and forget about CRUD!
An API works on a single object. With CRUD we're talking about managing those objects in a dedicated container like a list. And as I mentioned in my previous post, LabVIEW is not exactly great when it comes to handling arrays in a smart way, but variants can be a decent solution to a certain extent.
So let's start with the container, sometimes called repository (remember the repository pattern a few lines above? :)), or in a database context, table. A table is a collection of (usually) unique entities (or rows, records), each containing the same fields (columns). Finding an entity is easy with a query, but we're going to simplify this, and have only one search criteria in our case (until LabVIEW R&D decides to implement a local SQL-like or LINQ ability to work on iterable types).
Moving to a LabVIEW world full of variants, our repository is a variant. The data behind it can be anything, you choose (e.g. a string containing the name of the repo)! Each entity is a variant attribute inside this repo, named after one of the fields of this entity that makes it unique (in a database table, the primary key is usually unique). Then, accessing this entity by name is simple and fast using variant attributes, and satisfies all the CRUD operations:
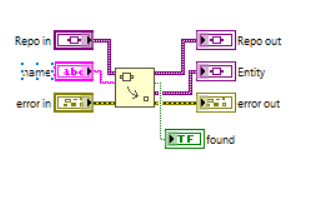
Last but no least, if you'd like to decouple the repository from the type of data it contains, the last thing to do is to consider an entity as a variant, each of its attributes being a field. All that remains to implement is a dedicated converter that knows how to"variantify" or "unvariantify" the entity, and that is bound to your application (while the repository is not). The CRUD part is then totally generic (relying exclusively on variants) and can be reused.
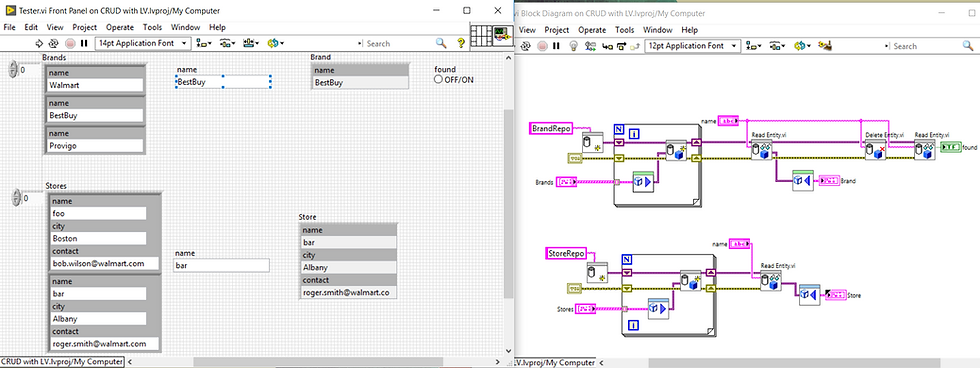
This simple illustration of the CRUD in LabVIEW could certainly be implemented with typed arrays instead of variants, but will be far slower, less descriptive (index-based search), and pretty specific to a single need. Variants just won the game this time.
If you'd like to download a stripped version of the code (used as a demo for this post), here it goes!
Now, this CRUD approach have several flaws: the converters are boring and pretty specific to implement, and there is no obvious way to correlate different entities lying different repositories. This latter point clearly kills the principle of a database (where relations between tables is a fundamental), so be ready for the next step! Next time on TheLabVIEWLab: a proper way to retrieve the brand and store information from a requested camera.
Commentaires